It's Time to Replace TCP in the Datacenter
Summary of It’s Time to Replace TCP in the Datacenter
This position paper from John Ousterhout sets out everything that’s wrong with TCP and exactly how we should fix it. It’s an interesting and purposefully polemical paper1. Ousterhout has serious pedigree in distributed systems. He was one of the co-authors of In Search of an Understandable Consensus Algorithm, the paper that introduced Raft, created the Tcl scripting language, and has led a number of teams to impressive results over the years, so he’s talking from a place of experience.
The paper proposes that there are core issues with TCP that can’t be fixed. It argues that these issues are so core to TCP as to require breaking changes, at which point you might as well fix everything at once. It then goes on to discuss Homa, a protocol designed specifically for the datacenter, that fixes all of these issues.
What’s wrong with TCP?
Let’s run through the properties that the author sets out as needing to be reworked:
First, TCP is stream oriented. Work comes in as bytes, but in the datacenter it’s typically executed in complete messages, which have to be read from the stream and reconstructed. This means messages can’t be rerouted to available cores. Over time network speeds have increased to the point that server cores can’t keep up. To make full use of a network link you need to spread the load equally across them, but stream orientation makes that difficult to do. The stream is tied to whichever core is reading from the stream and you either need to then dispatch work to other cores or process whatever incoming message you have, blocking further work on the same stream. This quote highlights the issue well:
The fundamental problem with streaming is that the units in which data is received (range of bytes) do not correspond to dispatchable units of work (messages)
In a similar vein, TCP is also connection oriented. This adds overhead, each open remote connection on a Linux server requires around 2000 bytes of overhead in the kernel. Connections have non trivial time to setup too, with 1 RTT to connect. While connections made sense previously when clients and hosts were long lived, now many applications are serverless. Paying the connection cost makes less sense in that world.2
TCP requires in order delivery, although as Ousterhout admits, with a limited amount of reordering allowed. This prevents techniques for reducing load throughout the network, such as packet spraying, where packets are routed via different network pathways, reducing congestion at the hot nodes.
Congestion control is highlighted as another problem point. TCP’s congestion control is driven by senders reacting to backpressure. This means there must be packet queueing when the network is loaded.
Bandwidth sharing (or “fair scheduling”) shares bandwidth on a host link equally between active connections. But Ousterhout argues that this impacts short messages disproportionately, leading to much higher tail latencies under load.
Why is Homa better?
The main thrust of Homa is that it fixes all of these issues. It’s message oriented, so work arrives in dispatchable units. It’s connectionless, so there’s no setup or ongoing overhead. It can be delivered out of order, allowing packet spraying–balancing load evenly across network links. It also lets receivers control congestion through a kind of token bucket method. Senders can only send packets in response to grants from a receiver, so the receiver can limit congestion and use grants to prioritize certain (shorter) messages.
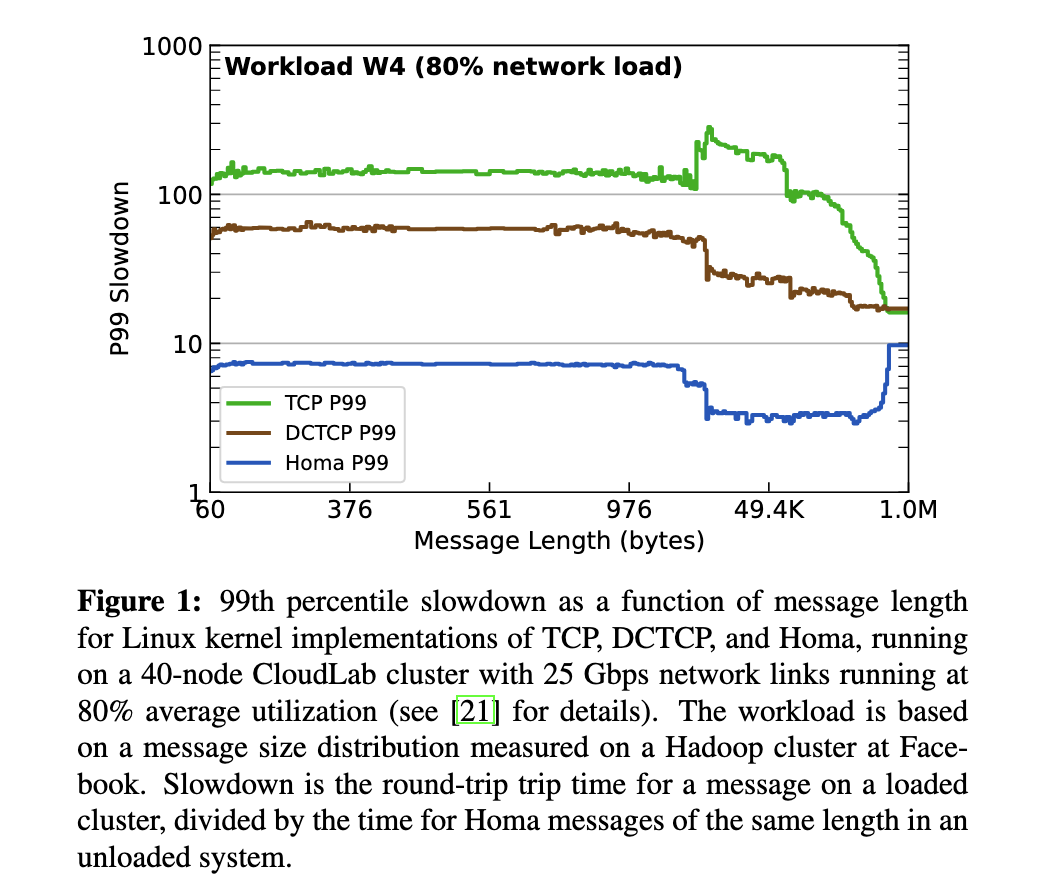
The only data provided in this paper is a graph displaying the 99th percentile slowdown on a loaded network. This took me a little while to parse so I’m going to talk my way through my understanding. As this is the slowdown, it’s graphing the ratio between the latency of messages in an unloaded, vs loaded network. It’s essentially showing how much slower the p99 is when the network is loaded, vs unloaded for each of these protocols, so we can see that for Homa, messages are about 6-10X slower under load for the p99, while for TCP it’s over 100X for small messages, dropping down to a little under 20X for 1M messages.
I found this a little confusing of a way to present the information, but it gets the message across! Homa is clearly designed to benefit tail latencies for smaller messages.
But what about encryption?
My big question reading this paper was the lack of any mention of encryption. TCP works very well with TLS and there are so many easy to set up integrations. There’s no excuse or reason to have datacenter traffic containing customer data communicating over plaintext. Although I believe there are existing standards for protocols like this, such as DTLS for datagrams and UDP, it would be great to have some kind of mention about how encryption fits into the picture.
What else is out there?
There are other protocols in the space. Discussing this paper with colleagues, I learned about the SRD protocol which is used by Elastic Block Store for high throughput. SRD takes advantage of many of the same improvements that Homa does, such as packet spraying through a network. This means packets can arrive unordered (which the protocol then handles) but the common case is in order. In cases like this, the work is already being done, however, EBS (even within AWS) is relatively unique in its needs. This paper does mention other alternatives, mainly Infiniband, but it doesn’t mention SRD.
Conclusion
I found this a fun read. Like a lot of foundational software, TCP becomes one of those things that you rarely think about not using. It’s a strong default for many good reasons. TCP is incredibly common, almost any host that you can think of has a TCP implementation, and because its so common its been heavily optimised over the years.
But it’s always worth revisiting building blocks as things change, particularly the most common ones. Saving resources at the lower levels can be so powerful because they are so common. Saving 1% on a $100M cost can justify spending a lot more engineering time than saving 90% on $1000.
However, I don’t know if this seems to be one of those cases. TCP is just so ubiquitous, and so well optimised already, that for 95% of use cases it’s not worth the effort to switch. With every new technology there are new operational scars to learn. The further out on the bleeding edge you are, the more you have to debug yourself. I think for extremely high throughput systems where you have control over the vertical system it will make sense. I definitely agree with the position that integrating any such protocol with a few major RP frameworks is the best start to get things off the ground. I’ll be interested to see over the next few years how this space continues to develop.
Related reading
- Attack of the Killer Microseconds
- A Cloud-Optimized Transport Protocol for Elastic and Scalable HPC
- It’s TCP vs. RPC All Over Again
-
Don’t blame an old lit grad for forcing the alliteration ↩
-
I’m not sure I fully agree here as many serverless applications end up keeping the compute around to amortise setup costs. For example, AWS Lambda will keep your function running for a time after execution and reuse the micro-VM if another request comes in. ↩